偏向锁与轻量级锁
[toc]
Java SE1.6为了减少获得锁和释放锁所带来的性能消耗,引入了“偏向锁”和“轻量级锁”,所以在Java SE1.6里锁一共有四种状态,无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
[toc]
Java SE1.6为了减少获得锁和释放锁所带来的性能消耗,引入了“偏向锁”和“轻量级锁”,所以在Java SE1.6里锁一共有四种状态,无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
StampedLock是java8在java.util.concurrent.locks新增的一个API。
ReentrantReadWriteLock 在沒有任何读写锁时,才可以取得写入锁,这可用于实现了悲观读取。然而,如果读取很多,写入很少的情况下,使用 ReentrantReadWriteLock 可能会使写入线程遭遇饥饿问题,也就是写入线程无法竞争到锁定而一直处于等待状态。
StampedLock(印戳锁)是对ReentrantReadWriteLock读写锁的一种改进,主要的改进为:在没有写只有读的场景下,StampedLock支持不用加读锁而是直接进行读操作,最大程度提升读的效率,只有在发生过写操作之后,再加读锁才能进行读操作
StampedLock有三种模式的锁,用于控制读取/写入访问。StampedLock的状态由版本和模式组成。锁获取操作返回一个用于展示和访问锁状态的票据(stamp)变量,它用相应的锁状态表示并控制访问,数字0表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。锁释放以及其他相关方法需要使用邮编(stamps)变量作为参数,如果他们和当前锁状态不符则失败,这三种模式为:
StampedLock 的读写锁都是不可重入锁,所以在获取锁后释放锁前不应该再调用会获取锁的操作,以避免造成调用线程被阻塞
[TOC]
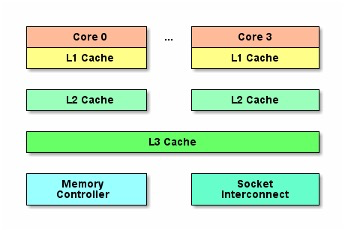
现代处理器为了提高访问数据的效率,在每个CPU核心上都会有多级 容量小、速度快 的缓存(分别称之为L1 cache,L2 cache,多核心共享L3 cache等),用于缓存数据。
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64个字节。
因此当CPU在执行一条读内存指令时,它是会将内存地址所在的内容加载进缓存中的,加载的大小取决于是缓存行大小的。也就是说,一次加载一整个缓存行。
在多核处理器系统中,每个处理器核心都有它们自己的一级缓存、二级缓存等。这样一来当多个处理器核心在对共享的数据进行写操作时,就需要保证该共享数据在所有处理器核心中的可见性/一致性。
【窥探技术 + MESI协议 】的出现,就是为了解决多核处理器时代,缓存不一致的问题的。
“窥探”背后的基本思想是,所有内存传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁:同一个指令周期中,只有一个缓存可以读写内存。
窥探技术的思想是,缓存不仅仅在做内存传输的时候才和总线打交道,而是不停地在窥探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其他处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其他处理器马上就知道这块内存在它们自己的缓存中对应的缓存行已经失效。
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序会遵守数据的依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。重排序分为如下三种类型。
1. 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2. 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3. 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操 作看上去可能是在乱序执行。
而我们编写的Java源程序中的语句顺序并不对应指令中的相应顺序,如(int a = 0; int b = 0;翻译成机器指令后并不能保证a = 0操作在b = 0操作之前)。因为编译器、处理器会对指令进行重排序,通常而言,Java源程序变成最后的机器执行指令会经过如下的重排序。
要理解双重检查锁定是从哪里起源的,就必须理解通用单例创建,如清单 1:
1 | import java.util.*; |
在CopyOnWriteArrayList类的set方法中有一段setArray(elements)代码(else块),实际上这段代码并未对elements做任何改动,注意这里的,实现的volatile语意并不对CopyOnWriteArrayList实例产生任何影响,为什么还是要保留这行语句?
1 | private transient volatile Object[] array; |
在这里首先理解下volatile,我们知道volatile变量自身具有下列特性:
可见性:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
缓冲区是所有I/O的基础,I/O无非就是把数据移进或移出缓冲区。下面看一个java进程发起read请求加载数据大致的流程图: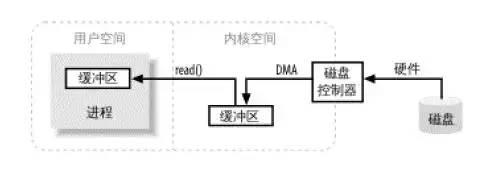
进程发起read请求之后,内核接收到read请求之后,会先检查内核空间中是否已经存在进程所需要的数据,如果已经存在,则直接把数据copy给进程的缓冲区;如果没有,内核随即向磁盘控制器发出命令,要求从磁盘读取数据,磁盘控制器把数据直接写入内核read缓冲区,这一步通过DMA完成;接下来就是内核将数据copy到进程的缓冲区;
如果进程发起 write网络请求,同样需要把用户缓冲区里面的数据copy到内核的socket缓冲区里面,然后再通过DMA把数据copy到网卡中,发送出去;
这样每次都需要把内核空间的数据拷贝到用户空间中,零拷贝的出现就是为了解决这种问题。
关于零拷贝提供了两种方式分别是:mmap+write方式,sendfile方式。
Java8中使用@sun.misc.Contended注解来避免伪共享(false sharing)。关于伪共享这个概念,可以先参照http://ifeve.com/falsesharing/
伪共享的例子:
1 | public class VolatileLong { |
如果有两个VolatileLong对象,会被load到同一个缓存行里面,如果一个线程要修改对象1,另一个线程同时要修改对象2,此时就要面对伪共享问题(core1对缓存行中对象1的修改,导致core2中同一缓存行失效,即缓存的对象2需要重新load)。
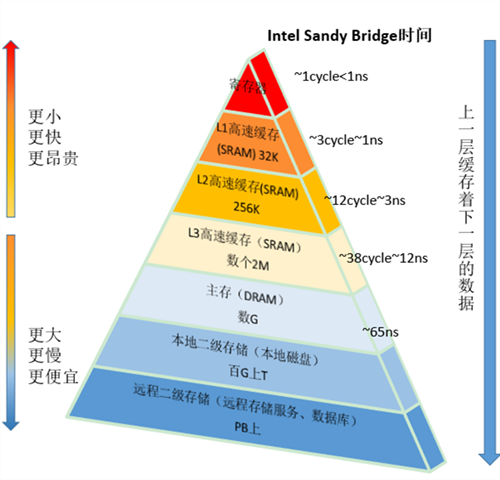
CPU是计算机的大脑,它负责执行程序的指令;内存负责存数据,包括程序自身数据。内存比CPU慢很多,现在获取内存中的一条数据大概需要200多个CPU周期(CPU cycles),而CPU寄存器一般情况下1个CPU周期就够了。
网页浏览器为了加快速度,会在本机存缓存以前浏览过的数据;传统数据库或NoSQL数据库为了加速查询,常在内存设置一个缓存,减少对磁盘(慢)的IO。同样内存与CPU的速度相差太远,于是CPU设计者们就给CPU加上了缓存(CPU Cache)。如果需要对同一批数据操作很多次,那么把数据放至离CPU更近的缓存,会给程序带来很大的速度提升。例如,做一个循环计数,把计数变量放到缓存里,就不用每次循环都往内存存取数据了。下面是CPU Cache的简单示意图: