记一次生产事故
转载自:https://juejin.cn/post/7311167273650454580
背景
我们的主要业务是台湾省的一个小商城,这次出问题的是我们仓库系统。在仓库系统中有这么一段逻辑:
员工可以领取新建的订单,然后去执行拣货发货的操作,领取的时候,发货单的状态会从新建变为待拣货,也就是说找新建状态的发货单,领取然后变为待拣货然后去拣货。
bug内容
突然有一天,仓库的同事发消息说有两位员工领取了同一个发货单。拣货的时候报错该发货单已拣货。 这可就奇了怪了,为了防止并发,且这个仓库是单节点部署的,记得是加了锁的。
模拟
这时候需要定位问题,先模拟一下我们的场景。
1 |
|
肯定是并发导致的,这里模拟一下高并发的情况
1 |
|
可以看到业务逻辑里有个锁,并且有事务。
数据大概长这样,我拿之前我写的demo的表来处理,修改这个age 100次。
执行,不用看表了,看log就知道有问题的:
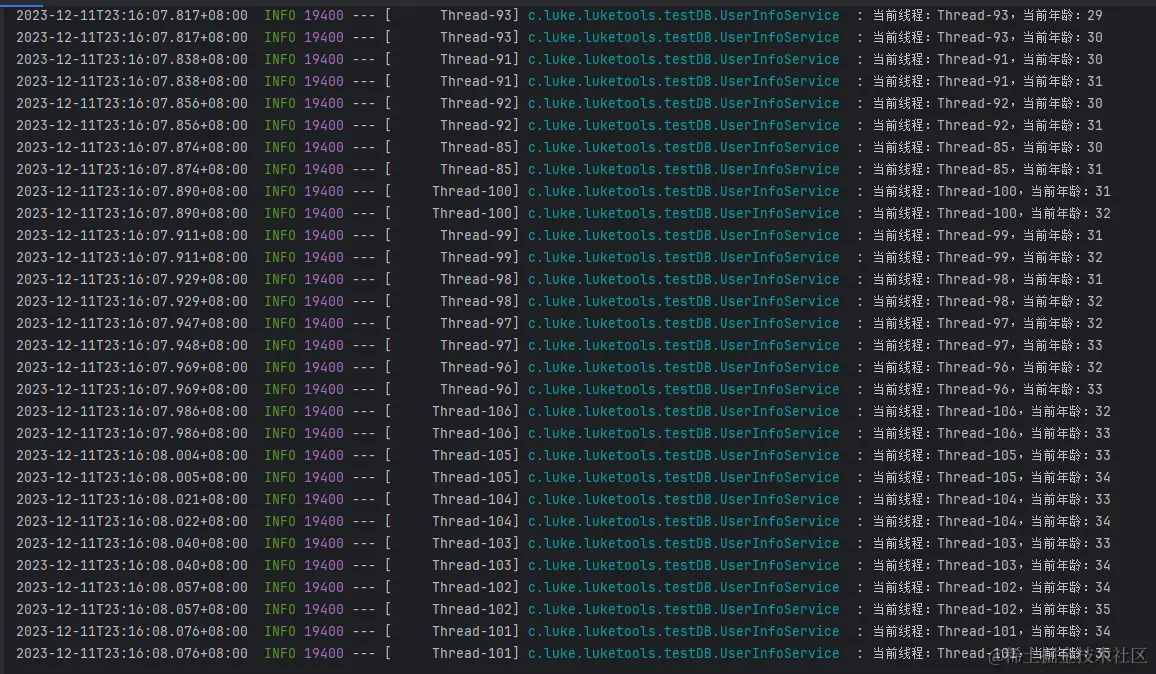
好家伙,这并发了啊,这锁了个寂寞啊。
好吧,查资料,很容易就查到了:
这种情况下,锁可能会失效。因为synchronized锁的是这个方法,而@Transactional是Spring的AOP在开启时自动锁定的。在进入这个方法前,AOP会先开启事务,然后进入方法,此时会加锁。当方法结束后,锁被释放,然后才会提交事务。如果在锁释放和提交事务之间有其他线程请求并再次加锁,这可能导致程序不安全。
所以,这应该就是问题所在了吧。
先改一版试试:
1 |
|
将锁放到整个事务的外层,这样事务提交之后才会释放锁。
1 |
|
看log,也是没有问题的
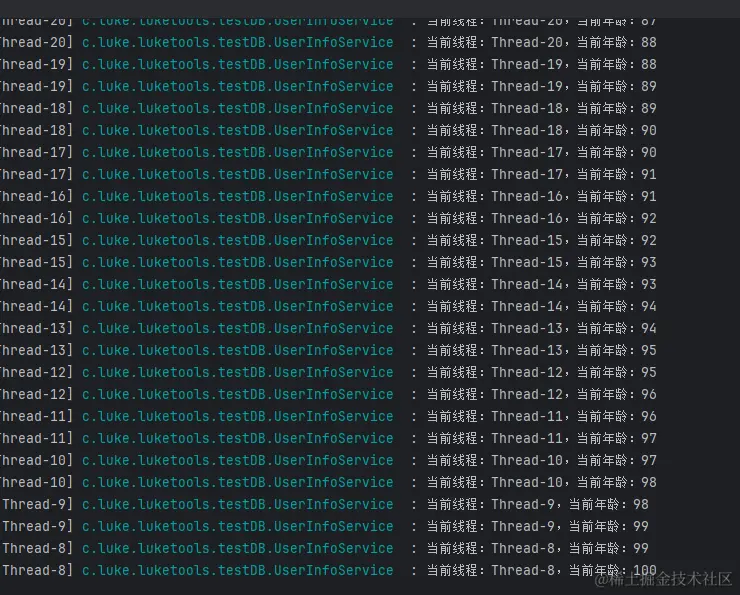
数据也没有问题
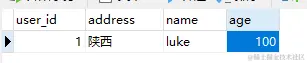
欸欸欸,好了。搞定,提代码,打包,发包,一气呵成。解决bug就是这么迅速。
又发生了
过了几天,仓库又反馈了,这bug又发生了,啊啊啊?奇了怪了。还没锁住?
在研究了好久,觉得这锁没问题啊,是哪里出了问题呢?各种权衡之下,先加了个分布式锁,以求解决问题。然而不出所料,过了两天又又又发生了。
又发生了,那就不是锁的问题了,那是什么的问题呢?这段业务很简单,拿到发货单,然后修改状态,然后存进去。就这,也没啥bug可以发生啊。
再从数据看,发现一个奇怪的地方,所有重复领取的发货单,都是在整点领取,然后发生bug的。这绝不是偶然,我在整点干啥了呢?
想起来了,我前一阵加了个功能,使用定时任务批量请求货代的打印面单接口然后将面单的url存到了发货单表里,这样,发货的时候就不用一个个请求这个接口了。这个任务就是整点跑的。。。。。
哎呦呦,我想通了,这样并发了啊,修改的同一张表,而且修改url的只会修改新建状态的url,
- 若是修改url的先获取发货单里所有新建状态的发货单
- 然后员工获取发货单数据,这时候因为修改url的线程需要调用api会稍微慢点
- 员工会把发货单修改为待拣货,然后保存入库
- 修改url的线程执行完了,由于我是执行的jpa的save方法,他会把自己读取到新建状态的数据,修改个url再保存回表,这时候,表里的数据又变成新建状态了。这样之后的员工又能取到这条发货单数据,然后这样不就重了。
找到原因了解决就很简单了,修改url的时候只修改这一个字段,其他的不修改就好了。
至此,bug解决掉了,修改数据库数据的时候save方法还是少用啊。一波三折啊,之前那种写法也是有问题的,幸亏一起改掉了,不然之后肯定也会继续发生。