Java为什么需要lambda表达式?
答: 在一定程度上能够提升代码简洁性、提高代码可读性。
例如,在平时的开发过程中,把一个列表转换成另一个列表或map等等这样的转换操作是一种常见需求。
1 2 3 4 5 List<Long> idList = Arrays.asList(1L, 2L, 3L); List<Person> personList = new ArrayList<>(); for (long id : idList) { personList.add(getById(id)); }
代码重复多了之后,大家就会对这种常见代码进行抽象,形成一些类库便于复用。
1 2 3 4 5 6 7 8 9 10 interface Function { <T, R> R fun(T input); } <T, R> List<R> map(List<T> inputList, Function function) { List<R> mappedList = new ArrayList<>(); for (T t : inputList) { mappedList.add(function.fun(t)); } return mappedList; }
有了这个抽象,最开始的代码便可以”简化”成
1 2 3 4 5 6 7 List<Long> idList = Arrays.asList(1L, 2L, 3L); List<Person> personList = map(idList, new Function<Long, Person>() { @Override public Person fun(Long input) { return getById(input); } });
虽然实现逻辑少了一些,但是同样也遗憾地发现,代码行数还变多了。
1 val personList = idList.map { id -> getById(id) }
这样的编写效率差距也导致了一部分Java用户流失到其他语言,不过最终终于在JDK8也提供了Lambda表达式能力,来支持这种函数传递。
1 List<Person> personList = map(idList, input -> getById(input));
Lambda表达式只是匿名内部类的语法糖吗?
如果要在Java语言中实现lambda表达式,初步观察,通过javac把这种箭头语法还原成匿名内部类,就可以轻松实现,因为它们功能基本是等价的(IDEA中经常有提示)。
但是匿名内部类有一些缺点。
每个匿名内部类都会在编译时创建一个对应的class,并且是有文件的,因此在运行时不可避免的会有加载、验证、准备、解析、初始化的类加载过程。
每次调用都会创建一个这个匿名内部类class的实例对象,无论是有状态的(capturing,从上下文中捕获一些变量)还是无状态(non-capturing)的内部类。
invokedynamic介绍
如果有一种函数引用、指针就好了,但JVM中并没有函数类型表示。
还有其他表示函数引用的方法吗?MethodHandle,它是在JDK7中与invokedynamic指令等一起提供的新特性。
但直接使用MethodHandle来实现,由于没有签名信息,会遇不能重载的问题。并且MethodHandle的invoke方法性能不一定能保证比字节码调用好。
invokedynamic出现的背景
JVM上的动态语言(JRuby, Scala等),要实现dynamic typing动态类型,是比较麻烦的。
例如如下动态语言的例子,a和b的类型都是未知的,因此a.append(b)这个方法是什么也是未知的。
1 2 def add(val a, val b) a.append(b)
而在Java中a和b的类型在编译时就能确定。
1 2 3 SimpleString add(SimpleString a, SimpleString b) { return a.append(b); }
编译后的字节码如下,通过invokevirtual明确调用变量a的函数签名为(LSimpleString;)LSimpleString;的方法。
1 2 3 4 0: aload_1 1: aload_2 2: invokevirtual #2 // Method SimpleString.append:(LSimpleString;)LSimpleString; 5: areturn
关于方法调用的字节码指令,JVM中提供了四种。
invokedynamic功能
这个限制让JVM上的动态语言实现者感到很艰难,只能暂时通过性能较差的反射等方式实现动态类型。
在jdk7,Java提供了invokedynamic指令来解决这个问题,同时搭配的还有java.lang.invoke包。
关键的概念有如下几个
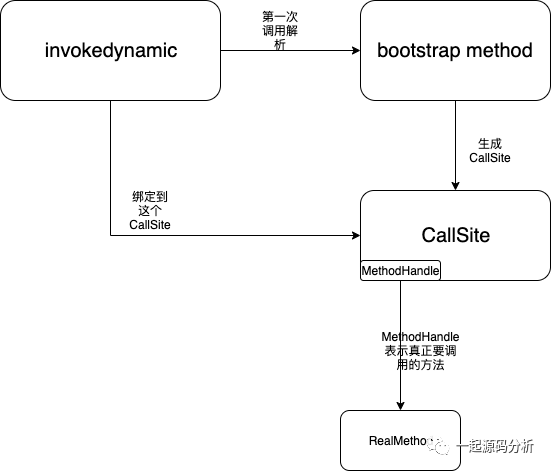
invokedynamic指令: 运行时JVM第一次到这里的时候会进行linkage,会调用用户指定的bootstrap method来决定要执行什么方法,之后便不需要这个解析步骤。这个invokedynamic指令出现的地方也叫做dynamic call site
Bootstrap Method: 用户可以自己编写的方法,实现自己的逻辑最终返回一个CallSite对象。
CallSite: 负责通过getTarget()方法返回MethodHandle
MethodHandle: MethodHandle表示的是要执行的方法的指针
再串联起来梳理下
invokedynamic在最开始时处于未链接(unlinked)状态,这时这个指令并不知道要调用的目标方法是什么。invokedynamic指令的时候,invokedynamic必须先进行链接(linkage)。boostrap method,传入当前的调用相关信息,bootstrap method会返回一个CallSite,这个CallSite中包含了MethodHandle的引用,也就是CallSite的target。invokedynamic指令便链接到这个CallSite上,并把所有的调用delegate到它当前的targetMethodHandle上。根据target是否需要变换,CallSite可以分为MutableCallSite、ConstantCallSite和VolatileCallSite等,可以通过切换target MethodHandle实现动态修改要调用的方法。
lambda表达式真正是如何实现的
下面直接看一下目前java实现lambda的方式
以下面的代码为例
1 2 3 4 5 6 public class RunnableTest { void run() { Function<Integer, Integer> function = input -> input + 1; function.apply(1); } }
编译后通过javap查看生成的字节码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 void run(); descriptor: ()V flags: Code: stack=2, locals=2, args_size=1 0: invokedynamic #2, 0 // InvokeDynamic #0:apply:()Ljava/util/function/Function; 5: astore_1 6: aload_1 7: iconst_1 8: invokestatic #3 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; 11: invokeinterface #4, 2 // InterfaceMethod java/util/function/Function.apply:(Ljava/lang/Object;)Ljava/lang/Object; 16: pop 17: return LineNumberTable: line 12: 0 line 13: 6 line 14: 17 LocalVariableTable: Start Length Slot Name Signature 0 18 0 this Lcom/github/liuzhengyang/invokedyanmic/RunnableTest; 6 12 1 function Ljava/util/function/Function; LocalVariableTypeTable: Start Length Slot Name Signature 6 12 1 function Ljava/util/function/Function<Ljava/lang/Integer;Ljava/lang/Integer;>; private static java.lang.Integer lambda$run$0(java.lang.Integer); descriptor: (Ljava/lang/Integer;)Ljava/lang/Integer; flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC Code: stack=2, locals=1, args_size=1 0: aload_0 1: invokevirtual #5 // Method java/lang/Integer.intValue:()I 4: iconst_1 5: iadd 6: invokestatic #3 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; 9: areturn LineNumberTable: line 12: 0 LocalVariableTable: Start Length Slot Name Signature 0 10 0 input Ljava/lang/Integer;
对应Function<Integer, Integer> function = input -> input + 1;这一行的字节码为
1 2 0: invokedynamic #2, 0 // InvokeDynamic #0:apply:()Ljava/util/function/Function; 5: astore_1
这里再复习一下invokedynamic的步骤。
JVM第一次解析时,调用用户定义的bootstrap method
bootstrap method会返回一个CallSiteCallSite中能够得到MethodHandle,表示方法指针JVM之后调用这里就不再需要重新解析,直接绑定到这个CallSite上,调用对应的target MethodHandle,并能够进行inline等调用优化
第一行invokedynamic后面有两个参数,第二个0没有意义固定为0 第一个参数是#2,指向的是常量池中类型为CONSTANT_InvokeDynamic_info的常量。
1 #2 = InvokeDynamic #0:#32 // #0:apply:()Ljava/util/function/Function;
这个常量对应的#0:#32中第二个#32表示的是这个invokedynamic指令对应的动态方法的名字和方法签名(方法类型)
1 #32 = NameAndType #43:#44 // apply:()Ljava/util/function/Function;
第一个#0表示的是bootstrap method在BootstrapMethods表中的索引。在javap结果的最后看到是
1 2 3 4 5 6 BootstrapMethods: 0: #28 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite; Method arguments: #29 (Ljava/lang/Object;)Ljava/lang/Object; #30 invokestatic com/github/liuzhengyang/invokedyanmic/RunnableTest.lambda$run$0:(Ljava/lang/Integer;)Ljava/lang/Integer; #31 (Ljava/lang/Integer;)Ljava/lang/Integer;
再看下BootstrapMethods属性对应JVM虚拟机规范里的说明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 BootstrapMethods_attribute { u2 attribute_name_index; u4 attribute_length; u2 num_bootstrap_methods; { u2 bootstrap_method_ref; u2 num_bootstrap_arguments; u2 bootstrap_arguments[num_bootstrap_arguments]; } bootstrap_methods[num_bootstrap_methods]; } bootstrap_method_ref The value of the bootstrap_method_ref item must be a valid index into the constant_pool table. The constant_pool entry at that index must be a CONSTANT_MethodHandle_info structure bootstrap_arguments[] Each entry in the bootstrap_arguments array must be a valid index into the constant_pool table. The constant_pool entry at that index must be a CONSTANT_String_info, CONSTANT_Class_info, CONSTANT_Integer_info, CONSTANT_Long_info, CONSTANT_Float_info, CONSTANT_Double_info, CONSTANT_MethodHandle_info, or CONSTANT_MethodType_info structure CONSTANT_MethodHandle_info The CONSTANT_MethodHandle_info structure is used to represent a method handle
这个BootstrapMethod属性可以告诉invokedynamic指令需要的boostrap method的引用以及参数的数量和类型。
1 #28 = MethodHandle #6:#40 // invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
按照JVM规范,BootstrapMethod接收3个标准参数和一些自定义参数,标准参数如下
MethodHandles.Loop类型的caller参数,这个对象能够通过类似反射的方式拿到在执行invokedynamic指令这个环境下能够调动到的方法,比如其他类的private方法是调用不到的。这个参数由JVM来入栈String类型的invokedName参数,表示invokedynamic要实现的方法的名字,在这里是apply,是lambda表达式实现的方法名,这个参数由JVM来入栈
MethodType类型的invokedType参数,表示invokedynamic要实现的方法的类型,在这里是()Function,这个参数由JVM来入栈
#29,#30,#31是可选的自定义参数类型
1 2 3 #29 = MethodType #41 // (Ljava/lang/Object;)Ljava/lang/Object; #30 = MethodHandle #6:#42 // invokestatic com/github/liuzhengyang/invokedyanmic/RunnableTest.lambda$run$0:(Ljava/lang/Integer;)Ljava/lang/Integer; #31 = MethodType #21 // (Ljava/lang/Integer;)Ljava/lang/Integer;
通过java.lang.invoke.LambdaMetafactory#metafactory的代码说明下
1 2 3 4 5 6 public static CallSite metafactory(MethodHandles.Lookup caller, String invokedName, MethodType invokedType, MethodType samMethodType, MethodHandle implMethod, MethodType instantiatedMethodType)
前面三个介绍过了,剩下几个为#29 = MethodType #41 // (Ljava/lang/Object;)Ljava/lang/Object;,表示要实现的方法对象的类型,不过它没有泛型信息,(Ljava/lang/Object;)Ljava/lang/Object;com.github.liuzhengyang.invokedyanmic.Runnable.lambda$run$0(Integer)Integer/invokeStatic,这里是javac生成的一个对lambda解语法糖之后的方法,后面进行介绍
private static java.lang.Integer lambda$run$0(java.lang.Integer);这个方法是有javac把lambda表达式desugar解语法糖生成的方法,如果lambda表达式用到了上下文变量,则为有状态的,这个表达式也叫做capturing-lambda,会把变量作为这个生成方法的参数传进来,没有状态则为non-capturing。
继续看5: astore_1这条指令,表示把当前操作数栈的对象引用保存到index为1的局部变量表中,即赋值给了function变量。invokedynamic #2, 0后,在操作数栈中插入了一个类型为Function的对象。LambdaMetafactory#metafactory的实现。
1 2 3 4 5 6 mf = new InnerClassLambdaMetafactory(caller, invokedType, invokedName, samMethodType, implMethod, instantiatedMethodType, false, EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY); mf.validateMetafactoryArgs(); return mf.buildCallSite();
创建了一个InnerClassLambdaMetafactory,然后调用buildCallSite返回CallSite
看一下InnerClassLambdaMetafactory是做什么的: Lambda metafactory implementation which dynamically creates an inner-class-like class per lambda callsite.
怎么回事!饶了一大圈还是创建了一个inner class!先不要慌,先看完,最后分析下和普通inner class的区别。
创建InnerClassLambdaMetafactory的过程大概是参数的一些赋值和初始化等buildCallSite,这个复杂一些,方法描述说明为Build the CallSite. Generate a class file which implements the functional interface, define the class, if there are no parameters create an instance of the class which the CallSite will return, otherwise, generate handles which will call the class' constructor.
创建一个实现functional interface的的class文件,define这个class,如果是没有参数non-capturing类型的创建一个类实例,CallSite可以固定返回这个实例,否则有状态,CallSite每次都要通过构造函数来生成新对象。
方法实现的第一步是调用spinInnerClass(),通过ASM生成一个function interface的实现类字节码并且进行类加载返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 只保留关键代码 cw.visit(CLASSFILE_VERSION, ACC_SUPER + ACC_FINAL + ACC_SYNTHETIC, lambdaClassName, null, JAVA_LANG_OBJECT, interfaces); for (int i = 0; i < argDescs.length; i++) { FieldVisitor fv = cw.visitField(ACC_PRIVATE + ACC_FINAL, argNames[i], argDescs[i], null, null); fv.visitEnd(); } generateConstructor(); if (invokedType.parameterCount() != 0) { generateFactory(); } // Forward the SAM method MethodVisitor mv = cw.visitMethod(ACC_PUBLIC, samMethodName, samMethodType.toMethodDescriptorString(), null, null); mv.visitAnnotation("Ljava/lang/invoke/LambdaForm$Hidden;", true); new ForwardingMethodGenerator(mv).generate(samMethodType); byte[] classBytes = cw.toByteArray(); return UNSAFE.defineAnonymousClass(targetClass, classBytes, null);
生成方法为
声明要实现的接口
创建保存参数用的各个字段
生成构造函数,如果有参数,则生成一个static Factory方法
实现function interface里的要实现的方法,forward到implMethodName上,也就是javac生成的方法或者MethodReference指向的方法
生成完毕,通过ClassWrite.toByteArray拿到class字节码数组
通过UNSAFE.defineAnonymousClass(targetClass, classBytes, null) define这个内部类class。这里的defineAnonymousClass比较特殊,它创建出来的匿名类会挂载到targetClass这个宿主类上,然后可以用宿主类的类加载器加载这个类。但是不会但是并不会放到SystemDirectory里,SystemDirectory是类加载器对象+类名字到kclass地址的映射,没有放到这个Directory里,就可以重复加载了,来方便实现一些动态语言的功能,并且能够防止一些内存泄露情况。
这些比较抽象,直观的看一下生成的结果
1 2 3 4 5 6 7 8 9 10 // $FF: synthetic class final class RunnableTest$$Lambda$1 implements Function { private RunnableTest$$Lambda$1() { } @Hidden public Object apply(Object var1) { return RunnableTest.lambda$run$0((Integer)var1); } }
如果有参数的情况呢,例如从外部类中使用了一个非静态字段,并使用了一个外部局部变量
1 2 3 4 5 6 private int a; void run() { int b = 0; Function<Integer, Integer> function = input -> input + 1 + a + b; function.apply(1); }
对应的结果为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 final class RunnableTest$$Lambda$1 implements Function { private final RunnableTest arg$1; private final int arg$2; private RunnableTest$$Lambda$1(RunnableTest var1, int var2) { this.arg$1 = var1; this.arg$2 = var2; } private static Function get$Lambda(RunnableTest var0, int var1) { return new RunnableTest$$Lambda$1(var0, var1); } @Hidden public Object apply(Object var1) { return this.arg$1.lambda$run$0(this.arg$2, (Integer)var1); } }
创建完inner class之后,就是生成需要的CallSite了。如果没有参数,则生成这个inner class的一个function interface对象示例,创建一个固定返回这个对象的MethodHandle,再包装成ConstantCallSite返回。
这样就完成了bootstrap的过程。invokedynamic链接完之后,后面的调用就直接调用到对应的MethodHandle了,具体是实现就是返回固定的内部类对象,或每次创建新内部类对象。
再次对比通过invokedynamic相对于直接匿名内部类语法糖的优势
我们再想一下,Java8实现这一套骚操作的原因是什么。既然lambda表达式又不需要什么动态分派(调动哪个方法是明确的), 为什么要用invokedynamic呢?
JVM虚拟机的一个基本保证就是低版本的class文件也是能够在高版本的JVM上运行的,并且JVM虚拟机通过版本升级,是在不断优化和提升性能的。
直接转换成内部类实现,固然简单,但编译后的二进制字节码(包括第三方jar包等)内容就固定了,实现固定为创建内部类对象+invoke{virtual, static, special, interface}调用。
未来提升性能只能靠提升创建类对象、invoke指令调用这几个地方的优化。换个熟悉点的说法就是这里写死了。
如果通过invokedynamic呢,javac编译后把足够的信息保留了下来,在JVM执行时能够动态决定如何实现lambda,也就能不断优化lambda表达式的实现,并保持兼容性,给未来留下了更多可能。
转载自:https://mp.weixin.qq.com/s/U7lExRHlIC6S3rnV7r5QTg