为什么新生代需要有两个Survivor区
1 为什么要有Survivor区
首先思考设置Survivor区的意义在哪里?
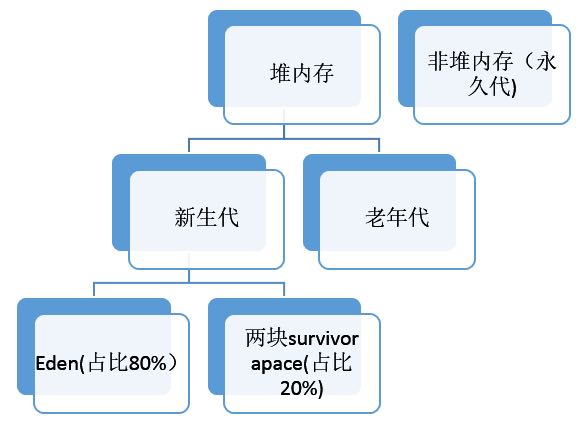
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被填满,触发Major GC(也可以看做触发了Full GC)。老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。频发的Full GC消耗的时间是非常多的,这一点会影响大型程序的执行和响应速度。
内存溢出的几种原因和解决办法
java.lang.OutOfMemoryError: …java heap space…
也就是当你看到heap相关的时候就肯定是堆栈溢出了,此时如果代码没有问题的情况下,适当调整-Xmx和-Xms是可以避免的,不过一定是代码没有问题的前提,为什么会溢出呢,要么代码有问题,要么访问量太多并且每个访问的时间太长或者数据太多,导致数据释放不掉,因为垃圾回收器是要找到那些是垃圾才能回收,这里它不会认为这些东西是垃圾,自然不会去回收了;主意这个溢出之前,可能系统会提前先报错关键字为:
java.lang.OutOfMemoryError:GC over head limit exceeded
这种情况是当系统处于高频的GC状态,而且回收的效果依然不佳的情况,就会开始报这个错误,这种情况一般是产生了很多不可以被释放的对象,有可能是引用使用不当导致,或申请大对象导致,但是java heap space的内存溢出有可能提前不会报这个错误,也就是可能内存就直接不够导致,而不是高频GC.
栈上分配和TLAB
栈上分配
JVM允许将线程私有的对象打散分配在栈上,而不是分配在堆上。分配在栈上的好处是可以在函数调用结束后自行销毁,而不需要垃圾回收器的介入,从而提高系统性能。
栈上分配的一个技术基础是进行逃逸分析,逃逸分析的目的是判断对象的作用域是否有可能逃逸出函数体。
另一个是标量替换,允许将对象打散分配在栈上,比如若一个对象拥有两个字段,会将这两个字段视作局部变量进行分配。
只能在server模式下才能启用逃逸分析,参数-XX:DoEscapeAnalysis启用逃逸分析,参数-XX:+EliminateAllocations开启标量替换(默认打开)。在JDK 6u23版本之后,HotSpot中默认就开启了逃逸分析,可以通过选项”-XX:+PrintEscapeAnalysis”查看逃逸分析的筛选结果。
TLAB
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区。这是一个线程专用的内存分配区域。
由于对象一般会分配在堆上,而堆是全局共享的。因此在同一时间,可能会有多个线程在堆上申请空间。因此,每次对象分配都必须要进行同步,而在竞争激烈的场合分配的效率又会进一步下降。JVM使用TLAB来避免多线程冲突,每个线程使用自己的TLAB,这样就保证了不使用同步,提高了对象分配的效率。
TLAB本身占用eden区空间,在开启TLAB的情况下,虚拟机会为每个Java线程分配一块TLAB空间。参数-XX:+UseTLAB开启TLAB,默认是开启的。TLAB空间的内存非常小,缺省情况下仅占有整个Eden空间的1%,当然可以通过选项-XX:TLABWasteTargetPercent设置TLAB空间所占用Eden空间的百分比大小。
由于TLAB空间一般不会很大,因此大对象无法在TLAB上进行分配,总是会直接分配在堆上。TLAB空间由于比较小,因此很容易装满。比如,一个100K的空间,已经使用了80KB,当需要再分配一个30KB的对象时,肯定就无能为力了。这时虚拟机会有两种选择,第一,废弃当前TLAB,这样就会浪费20KB空间;第二,将这30KB的对象直接分配在堆上,保留当前的TLAB,这样可以希望将来有小于20KB的对象分配请求可以直接使用这块空间。实际上虚拟机内部会维护一个叫作refill_waste的值,当请求对象大于refill_waste时,会选择在堆中分配,若小于该值,则会废弃当前TLAB,新建TLAB来分配对象。这个阈值可以使用TLABRefillWasteFraction来调整,它表示TLAB中允许产生这种浪费的比例。默认值为64,即表示使用约为1/64的TLAB空间作为refill_waste。默认情况下,TLAB和refill_waste都会在运行时不断调整的,使系统的运行状态达到最优。如果想要禁用自动调整TLAB的大小,可以使用-XX:-ResizeTLAB禁用ResizeTLAB,并使用-XX:TLABSize手工指定一个TLAB的大小。
-XX:+PrintTLAB可以跟踪TLAB的使用情况。一般不建议手工修改TLAB相关参数,推荐使用虚拟机默认行为。
那么总结一下虚拟机对象分配流程:首先如果开启栈上分配,JVM会先进行栈上分配,如果没有开启栈上分配或则不符合条件的则会进行TLAB分配,如果TLAB分配不成功,再尝试在eden区分配,如果对象满足了直接进入老年代的条件,那就直接分配在老年代。
注解@Async引发的Spring循环依赖分析
首先有一点可以确定,spring可以是解决某些循环依赖的,示例:
1 |
|
1 |
|
上面的例子,AService与BService存在循环依赖,运行也是没有问题的。现在开启异步(添加@EnableAsync),修改AService:
1 |
|
再次运行,就有会有如下报错:
1 | ERROR org.springframework.boot.SpringApplication - Application startup failed |
\@Value("#{}") 与 @Value("${}") 的区别
@Value(“#{}”)
@Value("#{}") 表示SpEl表达式,通常用来获取bean的属性,或者调用bean的某个方法。当然还有可以表示常量
1 |
|
Controller层设置切面的三种方式
[toc]
1.自定义PointcutAdvisor
1 | @Target({ElementType.METHOD, ElementType.TYPE}) |
1 | public class CustomizePointcutAdvisor extends DefaultPointcutAdvisor { |
1 | @Configuration |
1 | @RestController |
BeanPostProcessor
[toc]
BeanPostProcessor 从名字上就能看出来,这是一个 Bean 的后置处理器,也就是说,BeanPostProcessor 其实主要是对已经创建出来的 Bean 做一些后置处理,而 BeanFactoryPostProcessor 主要是针对 BeanDefinition 做后置处理(此时 Bean 对象还没创建出来)。
但是,BeanPostProcessor 家族里边也有例外,即 MergedBeanDefinitionPostProcessor,这是一个 BeanPostProcessor,但是却可以处理 BeanDefinition。
Spring Boot中自定义异常处理
Spring Boot 中提供了默认的异常处理,但是对于应用来说,这些信息并不应该直接返回或者不够明确,需要结合自己的情况进行定制。
自定义处理异常有两种方式:
- org.springframework.web.servlet.HandlerExceptionResolver#resolveException
- org.springframework.web.bind.annotation.RestControllerAdvice或org.springframework.web.bind.annotation.ControllerAdvice和org.springframework.web.bind.annotation.ExceptionHandler注解来实现
当两种方式都实现时,HandlerExceptionResolver要先于ControllerAdvice执行
Spring Boot启动过程源码分析
[toc]
Application实例化
Spring Boot的启动始于:
1 | SpringApplication.run(DemoApplication.class, args); |
相应实现:
1 | public static ConfigurableApplicationContext run(Object source, String... args) { |
1 | public static ConfigurableApplicationContext run(Object[] sources, String[] args) { |
它实际上会构造一个SpringApplication的实例,然后运行它的run方法:
1 | public SpringApplication(Object... sources) { |
1 | private void initialize(Object[] sources) { |