揭秘Nacos的AP架构「Distro一致性协议」
[toc]
每个 Nacos 节点虽然只负责属于自己的客户端,但是每个节点都是包含有所有的客户端信息的,所以当客户端想要查询注册信息时,可以直接从请求的 Nacos 的节点拿到全量数据。
Nacos 的架构
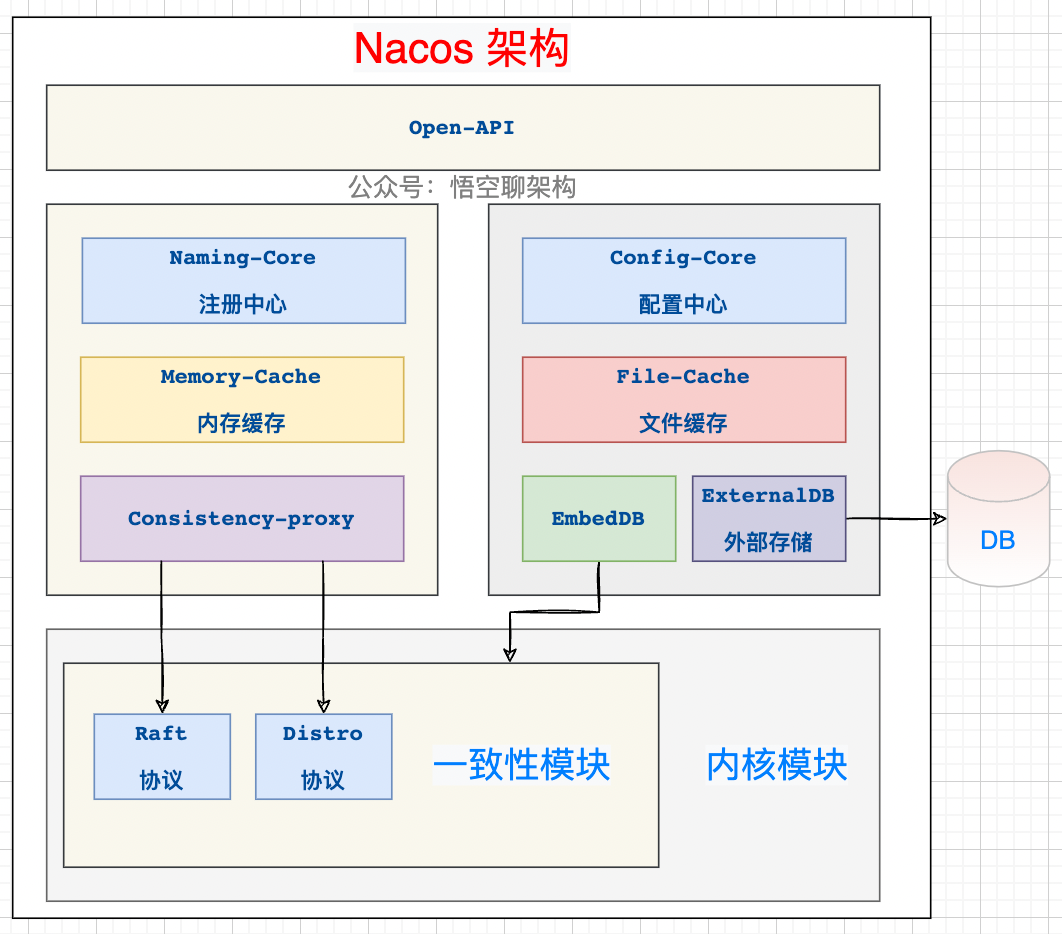
Nacos 是支持两种分布式定理的:CP(分区一致性)和 AP(分区可用性) ,而 AP 是通过 Nacos 自研的 Distro 协议来保证的,CP 是通过 Nacos 的 JRaft 协议来保证的。
因为注册中心作为系统中很重要的的一个服务,需要尽最大可能对外提供可用的服务,所以选择 AP 来保证服务的高可用,另外 Nacos 还采取了心跳机制来自动完成服务数据补偿的机制,所以说 Distro 协议是弱一致性的。
如果采用 CP 协议,则需要当前集群可用的节点数过半才能工作。
问题:Nacos 哪些地方用到了 AP 和 CP?
- 针对临时服务实例,采用 AP 来保证注册中心的可用性,Distro 协议。
- 针对持久化服务实例,采用 CP 来保证各个节点的强一致性,JRaft 协议。(JRaft 是 Nacos 对 Raft 的一种改造)
- 针对配置中心,无 Database 作为存储的情况下,Nacos 节点之间的内存数据为了保持一致,采用 CP。Nacos 提供这种模式只是为了方便用户本机运行,降低对存储依赖,生产环境一般都是通过外置存储组件来保证数据一致性。
- 针对配置中心,有 Database 作为存储的情况下,Nacos 通过持久化后通知其他节点到数据库拉取数据来保证数据一致性,另外采用读写分离架构来保证高可用,所以这里我认为这里采用的 AP,欢迎探讨。
- 针对 异地多活,采用 AP 来保证高可用。