redo log、undo log、binlog
[toc]
redo log
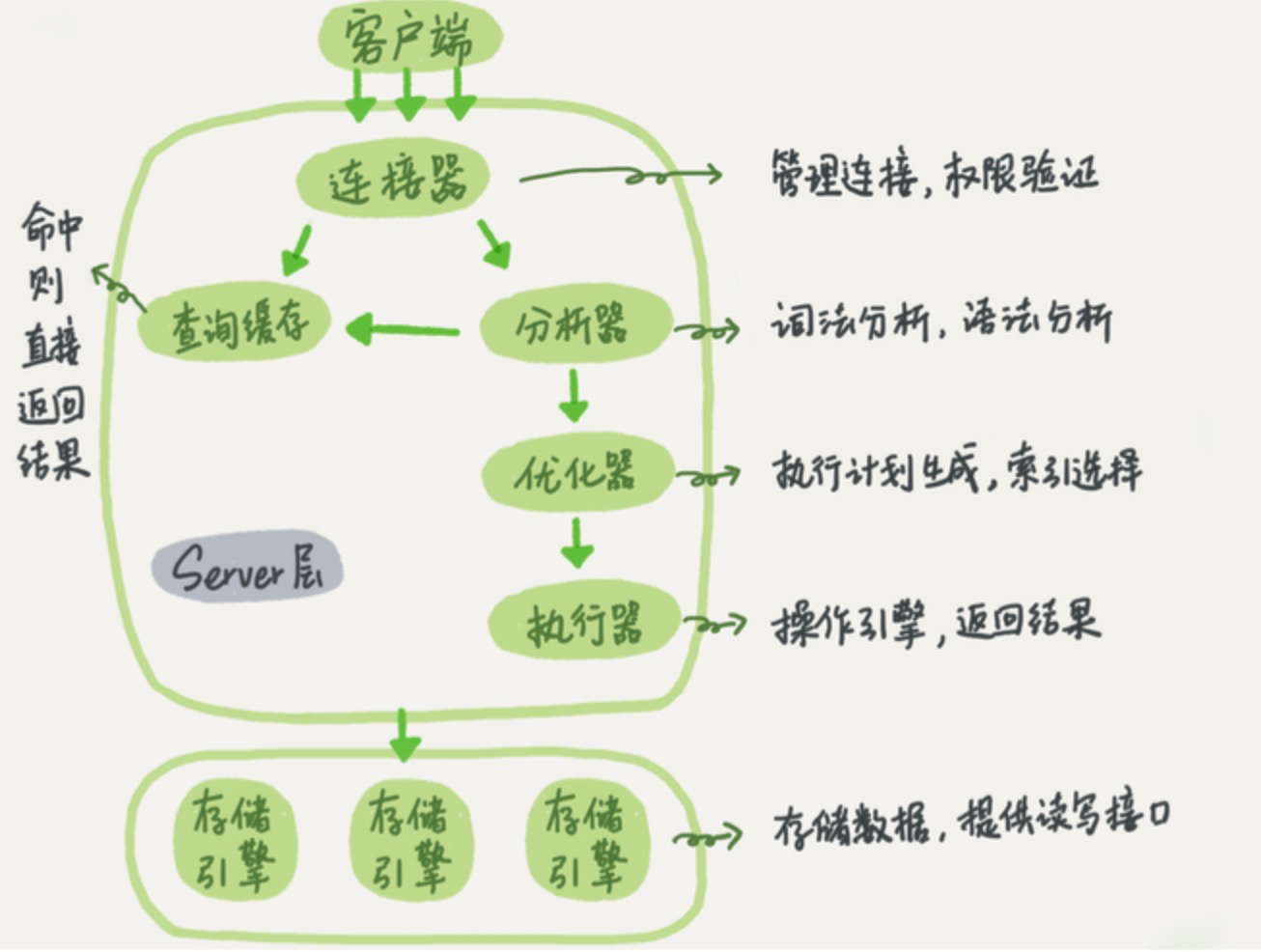
在innoDB的存储引擎中,事务日志通过 redolog 和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。
事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是Write-Ahead Logging。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
- 记录1:<trx1, insert…>
- 记录2:<trx2, delete…>
- 记录3:<trx3, update…>
- 记录4:<trx1, update…>
- 记录5:<trx3, insert…>