深入剖析socket的timeout
[toc]
1. socket超时分类
socket设置为阻塞模式时,就需要考虑处理socket操作超时的问题。
所谓阻塞模式,是指其完成指定的操作之前阻塞当前的进程或线程,直到操作有结果返回。
简单分类的话,可以将超时处理分成两类:
- 连接(connect)超时;
- 发送(send), 接收(recv)超时;
2. 连接超时
从字面上看,连接超时就是在一定时间内还是连接不上目标主机。socket连接其实最终都要进行系统调用进入内核态,剩下的就是等待内核通知连接建立。所以自行在代码中设置了超时时间(一般是叫connectTimeout或者socketTimeout),那么这个超时时间一到如果内核还没成功建立连接,那就认为是连接超时了。如果他们没设置超时时间,那么这个connectTimeout就取决于内核什么时候抛出超时异常了。
2.1 内核层的超时分析
个连接的建立需要经过3次握手,所以连接超时简单的说是是客户端往服务端发的SYN报文没有得到响应(服务端没有返回ACK报文)。
server 端为什么没有回复ack, 因为syn包的回复是内核层的,要么网络层丢包,要么就是内核层back_log的queue满了。
内核在发送SYN报文没有得到响应后,往往还是进行多次重试。同时,为了避免发送太多的包影响网络,重试的时间间隔还会不断增加。
在linux中,重试的时间间隔会呈指数型增长,为2的N次方,即:
第一次发送SYN报文后等待1s(2的0次幂)后再重试
第二次发送SYN报文后等待2s(2的1次幂)后再重试
第三次发送SYN报文后等待4s(2的2次幂)后再重试
第四次发送SYN报文后等待8s(2的3次幂)后再重试
第五次发送SYN报文后等待16s(2的4次幂)后再重试
第六次发送SYN报文后等待32s(2的5次幂)后再重试
第七次发送SYN报文后等待64s(2的6次幂)后再重试
对于重试次数,由linux的net.ipv4.tcp_syn_retries来确定,默认值一般是6,可以通过sysctl net.ipv4.tcp_syn_retries查看。比如重试次数是6次,那么以得出超时时间应该是 1+2+4+8+16+32+64=127秒 (上面的第一条是第一次发送SYN报文,不算重试)。
如果想修改重试次数,可以输入命令sysctl -w net.ipv4.tcp_syn_retries=5来修改。如果希望重启后生效,将net.ipv4.tcp_syn_retries = 5放入/etc/sysctl.conf中,之后执行sysctl -p 即可生效。
在一些linux发行版中,重试时间可能会变动。如果想确定操作系统具体的超时时间,可以通过下面这条命令来判断:
1 | gaoke:~$ date; telnet 10.16.15.15 5000; date |
2.2 综合分析
如果应用层面设置了自己的超时时间,同时内核也有自己的超时时间,那么应该以哪个为准呢?答案是哪个超时时间小以哪个为准。
个人认为,在我们的实际应用中,这个超时时间不宜设置的太长,通常建议2-10s。比如在分布式系统中,我们通常会在多台节点中根据一定策略选择一台进行连接。在有机器宕机的情况下,如果连接超时时间设置的比较长,而我们客户端的线程池又比较小,就很可能大多数的线程都在等待建立连接,过了较长时间才发现连接不上,影响应用的整体吞吐量。
2.3 connect系统调用
直接说结论。
linux层面可以设置SO_SNDTIMEO来控制connect系统调用的超时,如果不设置SO_SNDTIMEO,会由tcp重传定时器在重传超过设置的时候后超时,重传次数由tcp_syn_retries控制。
2.4 java connect API
看下java的connect api:
1 | public void connect(SocketAddress endpoint, int timeout) throws IOException { |
其connect最终调用下面的代码:
1 | Java_java_net_PlainSocketImpl_socketConnect(...){ |
注意这里,
在timeout<=0的时候,走默认的系统调用不设置超时时间的逻辑;
在timeout>0时,将socket设置为非阻塞,然后用select系统调用去模拟超时, 而没有走linux本身的超时逻辑,如下图所示:
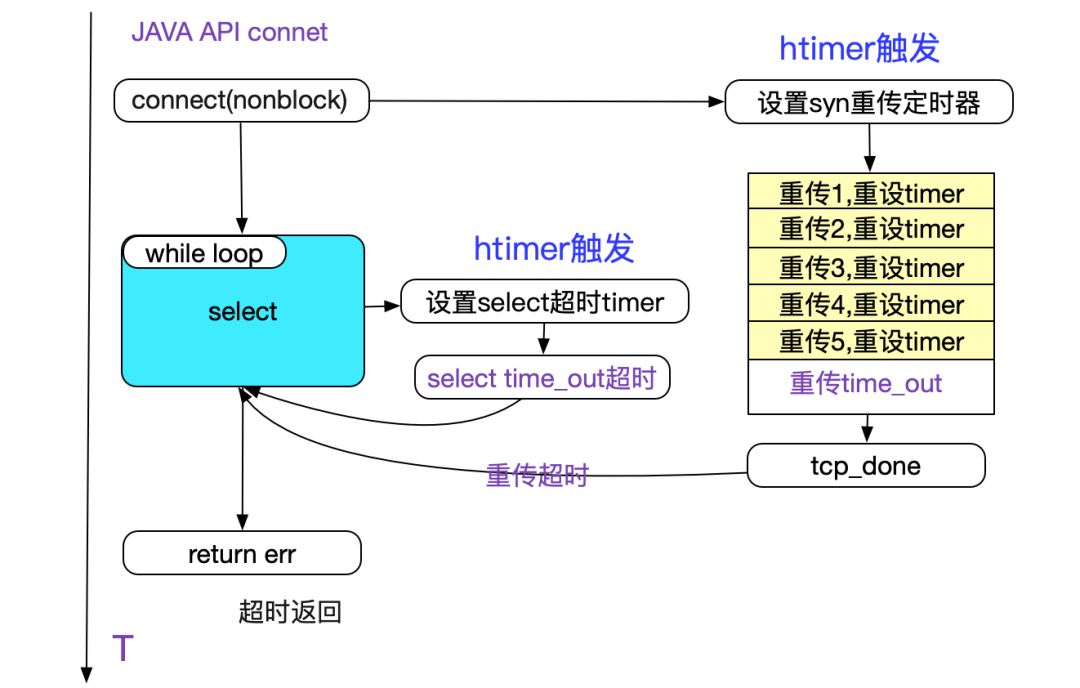
所以在timeout为0的时候,直接就通过重传次数来控制超时时间。而在timeout大于0的时候,超时时间如下表格所示:
| tcp_syn_retries | timeout |
|---|---|
| 1 | min(timeout, 3s) |
| 2 | min(timeout, 7s) |
| 3 | min(timeout, 15s) |
| 4 | min(timeout, 31s) |
| 5 | min(timeout, 63s) |
笔者在机器上(macOS)测试,实际超时时间情况如下:
当timeout为0,超时为75s;
当timeout为1000*50,超时为50s;
当timeout为1000*100,超时为75s;
3. 发送超时
在tcp连接建立之后,写操作可以理解为向对端发送tcp报文的过程。
在tcp的实现中,每一段报文都需要有对端的回应,即ACK报文。和连接时发送SYN报文一样,如果超过一定时间没有收到响应,内核会再次重发该报文。
和SYN报文的重试不同的是,linux有另外的参数来控制这个重试次数,即net.ipv4.tcp_retries2,可以通过sysctl net.ipv4.tcp_retries2查看其值。和SYN报文的超时时间一样,如果应用层设置了超时时间,哪么具体的超时时间以内核和应用层的超时时间的最小值为准。
socket的write系统调用最后调用的是tcp_sendmsg,源码中如果socket的write buffer依旧有空间的时候,会立马返回,并不会有timeout。但是write buffer不够的时候,会等待SO_SNDTIMEO的时间(nonblock时候为0)。SO_SNDTIMEO不设置,write buffer满之后ack一直不返回的情况(例如,物理机宕机),则会在重传定时器tcp_retransmit_timer到期后timeout,其重传到期时间通过tcp_retries2以及TCP_RTO_MIN计算出来。
| tcp_retries2 | buffer未满 | buffer满 |
|---|---|---|
| 5 | 立即返回 | min(SO_SNDTIMEO,(25.6s-51.2s)根据动态rto定 |
| 15 | 立即返回 | min(SO_SNDTIMEO,(924.6s-1044.6s)根据动态rto定 |
java的sockWrite0没有设置超时时间的地方,同时也没有设置过SO_SNDTIMEOUT,其直接调用了系统调用,所以其超时时间和系统调用保持一致。
4. 接收超时
在tcp协议中,读的操作和写操作的逻辑是相通的。
tcp连接建立后,两边的通信无非就是报文的互传。对于tcp协议而言,其实不会分辨他们发送的报文具体是要干嘛,因此readTimeout的判断逻辑和writeTimeout基本一样。它的重传次数也是由参数net.ipv4.tcp_retries2控制。在应用层面也一般是统一叫socketTimeout。
socket的read系统调用最终调用的是tcp_recvmsg,最终超时时间是依据对端响应与否、SO_RCVTIMEO以及通过tcp_retries2以及TCP_RTO_MIN计算出来。
| tcp_retries2 | 对端无响应 | 对端内核响应正常 |
|---|---|---|
| 5 | min(SO_RCVTIMEO,(25.6s-51.2s)根据动态rto定 | SO_RCVTIMEO==0?无限,SO_RCVTIMEO) |
| 15 | min(SO_RCVTIMEO,(924.6s-1044.6s)根据动态rto定 | SO_RCVTIMEO==0?无限,SO_RCVTIMEO) |
java的超时时间由SO_TIMOUT决定,而linux的socket并没有这个选项。看下jdk中SO_TIMOUT的描述:
1 | /** Set a timeout on blocking Socket operations: |
java对这里超时的实现,就和上面的java connect一样,在SO_TIMEOUT>0的时候依旧是由nonblock socket模拟出来的。所以最终超时时间的情况如下:
| tcp_retries2 | 对端无响应 | 对端内核响应正常 |
|---|---|---|
| 5 | min(SO_TIMEOUT,(25.6s-51.2s)根据动态rto定 | SO_TIMEOUT==0?无限,SO_RCVTIMEO |
| 15 | min(SO_TIMEOUT,(924.6s-1044.6s)根据动态rto定 | SO_TIMEOUT==0?无限,SO_RCVTIMEO |
5. 对端物理机宕机之后的timeout
对端物理机宕机后还依旧有数据发送
对端物理机宕机时对端内核也gg了(不会发出任何包通知宕机),那么本端发送任何数据给对端都不会有响应。其超时时间就由上面讨论的 min(设置的socket超时[例如SO_TIMEOUT],内核内部的定时器超时来决定)。
对端物理机宕机后没有数据发送,但在read等待
这时候如果设置了超时时间timeout,则在timeout后返回。但是,如果仅仅是在read等待,由于底层没有数据交互,那么其无法知道对端是否宕机,所以会一直等待。但是,内核会在一个socket两个小时都没有数据交互情况下(可设置)启动keepalive定时器来探测对端的socket。如下图所示:

大概是2小时11分钟之后会超时返回。keepalive的设置由内核参数指定:
1 | cat/proc/sys/net/ipv4/tcp_keepalive_time 7200 即两个小时后开始探测 |
可以在setsockops中对单独的socket指定是否启用keepalive定时器(java也可以)。
对端物理机宕机后没有数据发送,也没有read等待
和上面同理,也是在keepalive定时器超时之后,将连接close。所以我们可以看到一个不活跃的socket在对端物理机突然宕机之后,依旧是ESTABLISHED状态,过很长一段时间之后才会关闭。
进程宕后的超时
如果仅仅是对端进程宕机的话(进程所在内核会close其所拥有的所有socket),由于fin包的发送,本端内核可以立刻知道当前socket的状态。如果socket是阻塞的,那么将会在当前或者下一次write/read系统调用的时候返回给应用层相应的错误。如果是nonblock,那么会在select/epoll中触发出对应的事件通知应用层去处理。
如果fin包没发送到对端,那么在下一次write/read的时候内核会发送reset包作为回应。
nonblock
设置为nonblock=true后,由于read/write都是立刻返回,且通过select/epoll等处理重传超时/probe超时/keep alive超时/socket close等事件,所以根据应用层代码决定其超时特性。定时器超时事件发生的时间如上面几小节所述,和是否nonblock无关。nonblock的编程模式可以让应用层对这些事件做出响应。
转载自:
https://blog.csdn.net/yinshipin007/article/details/129370511
https://www.cnblogs.com/alchemystar/p/13704067.html
https://www.jb51.net/article/111163.htm